
Most people in our industry know what the acronym CVE means. For those that may not, CVE stands for Common Vulnerabilities and Exposures. According to their website, CVE was launched in 1999 as a list of common identifiers for publicly-known cybersecurity vulnerabilities found in commercial and open source software and / or firmware.
What makes CVE so important is that prior to 1999, most cybersecurity vendors used their own tracking databases and vulnerability identifiers when a software flaw was discovered, which, as you can imagine, caused significant disparity since no standard was yet established. This also produced potential gaps in security coverage and little interoperability among the different databases and tools tracking the growing list of discovered software vulnerabilities.
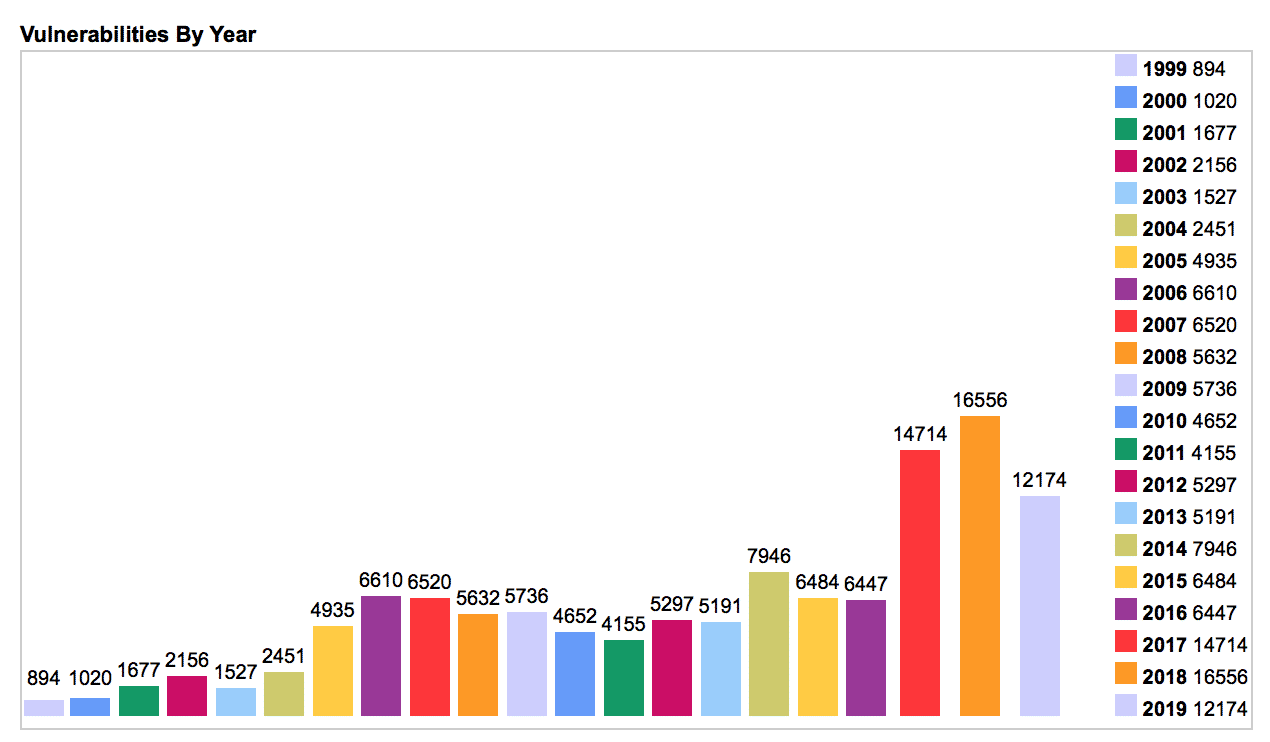
Thus, CVE was launched and today it’s an international cybersecurity community effort that has established an industry standard for common vulnerability and exposure identifiers. Looking back in 1999, there were a total of 894 vulnerabilities tracked that year. Below is a chart showing the number of software vulnerabilities recorded per year since its inception.
 Source
It’s easy to see that the number of vulnerabilities discovered, labeled, and tracked with their own unique CVE has seen a massive spike in recent years – in fact, in 2018 alone, 16,556 vulnerabilities were identified, a 1,752 percent increase compared to 1999. Also, you’ll notice, there have already been 12,174 CVEs for this year alone. That number will likely grow before the end of 2019. When adding up all software vulnerabilities being tracked since 1999, a total of 122,774 have been identified overall.
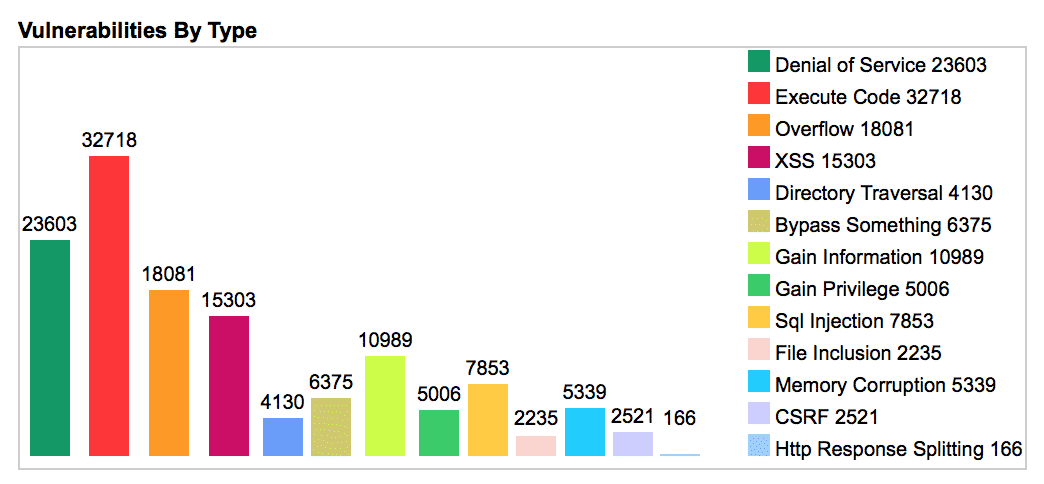
Next, let’s look at the breakdown of the number of vulnerabilities by type since 1999 as shown in the chart below.
Source
It’s easy to see that the number of vulnerabilities discovered, labeled, and tracked with their own unique CVE has seen a massive spike in recent years – in fact, in 2018 alone, 16,556 vulnerabilities were identified, a 1,752 percent increase compared to 1999. Also, you’ll notice, there have already been 12,174 CVEs for this year alone. That number will likely grow before the end of 2019. When adding up all software vulnerabilities being tracked since 1999, a total of 122,774 have been identified overall.
Next, let’s look at the breakdown of the number of vulnerabilities by type since 1999 as shown in the chart below.
 Source
As we can see, Execute Code has the highest number of CVEs, followed by Denial of Service. What’s most interesting though is that the vulnerabilities discovered in commercial and open source software continues to grow over time. As a matter of fact, the latest OWASP Top 10 lists many of the vulnerabilities in the chart above as the most significant risks organizations face. Simply put, these vulnerabilities are due to the weaknesses in software caused by the humans who develop it.
Another interesting aspect is that the vulnerabilities tracked by CVE have nothing to do with vulnerabilities found in software developed “in-house” by organizations who develop software for their own internal and external purposes. At the end of the day, what we can say is that the overabundance of software vulnerabilities leads to a major, industry-wide problem called “Software Exposure.”
Source
As we can see, Execute Code has the highest number of CVEs, followed by Denial of Service. What’s most interesting though is that the vulnerabilities discovered in commercial and open source software continues to grow over time. As a matter of fact, the latest OWASP Top 10 lists many of the vulnerabilities in the chart above as the most significant risks organizations face. Simply put, these vulnerabilities are due to the weaknesses in software caused by the humans who develop it.
Another interesting aspect is that the vulnerabilities tracked by CVE have nothing to do with vulnerabilities found in software developed “in-house” by organizations who develop software for their own internal and external purposes. At the end of the day, what we can say is that the overabundance of software vulnerabilities leads to a major, industry-wide problem called “Software Exposure.”
Source
It’s easy to see that the number of vulnerabilities discovered, labeled, and tracked with their own unique CVE has seen a massive spike in recent years – in fact, in 2018 alone, 16,556 vulnerabilities were identified, a 1,752 percent increase compared to 1999. Also, you’ll notice, there have already been 12,174 CVEs for this year alone. That number will likely grow before the end of 2019. When adding up all software vulnerabilities being tracked since 1999, a total of 122,774 have been identified overall.
Next, let’s look at the breakdown of the number of vulnerabilities by type since 1999 as shown in the chart below.
Source
As we can see, Execute Code has the highest number of CVEs, followed by Denial of Service. What’s most interesting though is that the vulnerabilities discovered in commercial and open source software continues to grow over time. As a matter of fact, the latest OWASP Top 10 lists many of the vulnerabilities in the chart above as the most significant risks organizations face. Simply put, these vulnerabilities are due to the weaknesses in software caused by the humans who develop it.
Another interesting aspect is that the vulnerabilities tracked by CVE have nothing to do with vulnerabilities found in software developed “in-house” by organizations who develop software for their own internal and external purposes. At the end of the day, what we can say is that the overabundance of software vulnerabilities leads to a major, industry-wide problem called “Software Exposure.”




