
In my previous blog, I walked you through the reasoning and importance of the Exploitable Path feature in the Checkmarx CxSCA solution. We discussed the challenges of prioritizing vulnerabilities in open source dependencies and defined what it means for a vulnerability to be exploitable:
 The code of OSLib will be:
The code of OSLib will be:
 Here are the steps:
Here are the steps:
 For the package code, the result is similar:
For the package code, the result is similar:

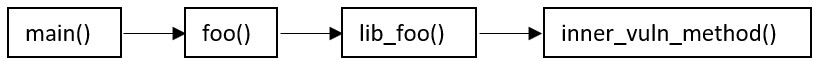 All methods in the graph are checked for exploitability. In our example, inner_vuln_method() is the exploitable method, and so an Exploitable Path is found.
All methods in the graph are checked for exploitability. In our example, inner_vuln_method() is the exploitable method, and so an Exploitable Path is found.

- The vulnerable method in the library needs to be called directly or indirectly from a user’s code.
- An attacker needs a carefully crafted input to reach the method to trigger the vulnerability.
Prerequisites
1. A SAST Engine
Every programming language has its set of quirks and features. Some use brackets; some don’t. Some are loosely typed; others are strict. To be able to develop an Exploitable Path, we needed a certain level of abstraction for example, a “common language.” This is particularly hard when high level concepts like “imports” behave differently across languages. To solve this issue, Checkmarx uses its powerful CxSAST engine. CxSAST breaks down the code of every major language into an Abstract Syntax Tree (AST), which provides much of the needed abstraction. Imports, call graphs, method definitions, and invocations all become a tree.2. An AST Query Language
Having an AST, the next step is having a query language capable of even further abstractions. Checkmarx uses CxQuery that can run queries to answer various questions, for example:- What are all the import statements in a codebase?
- Which methods have no definition but only usage?
- What’s the namespace of every file?
Assumptions
1. Vulnerable Methods Are Known
Usually, the public data on a CVE provides a CVSS score, affected products, and versions, etc. However, the inner method in which the vulnerability is triggered is usually unknown. To help with this dilemma, the CxSCA Research Team has application security analysts on board who are responsible for analyzing CVEs and finding the method in which the vulnerability occurs. So, for the rest of the post we can assume that for every CVE, we know the method that triggers it.2. A SAST Scan Is Limited to One Project
You can think of a project as a folder containing all source code without the third-party package's code. This makes life easier since there’s a clear distinction between a user’s code and the dependency's code. For example, in case there’s a user code that requires a single third-party package, two scans can be made:- A scan on the user code.
- A scan on the third-party package.
Static Analysis Steps
Now that we’ve covered the prerequisites and assumptions, let’s understand the challenge itself by looking at the following example, written in Python. Here’s a simple code, importing an open source library and calling a method in it. This method in turn calls a vulnerable method.
The code of OSLib will be:
Here are the steps:
1. Find Unresolved Methods in User’s Code
The user code is parsed with CxSAST and a query is run to detect all methods that are called and are missing a definition – hence unresolved and belong to a third-party package. In our example, there are two calls:- foo() – is defined in the user code and hence resolved.
- lib_foo() – is defined in OSLib and hence an unresolved method must be imported.
2. Find Exported Methods in Package Code
The code of package OSLib is also parsed with CxSAST, and a query is run to find all exported methods. In languages like C# and Java, an exported method is a public method in a public class that can be used by the user’s code. In Python, all methods are public so the exported methods in our example will be lib_foo() and inner_vuln_method(). This data is essential since it’s used to match unresolved methods in the step above.3. Call Graph
A query for a call graph is run on both user’s code and package code. For the user’s code, the graph is:
For the package code, the result is similar:
4. Find Exploitable Path
Using all the data collected so far, a full call graph is built:
All methods in the graph are checked for exploitability. In our example, inner_vuln_method() is the exploitable method, and so an Exploitable Path is found.
Further Topics
The example above provided a simple demonstration of how Exploitable Path is analyzed, but in reality, this problem is much harder. Some other research questions we faced, which are not discussed in this blog post, are:- Detecting Exploitable Path in a dependency of a dependency
- Matching challenges between user’s code and package code
- Integration of DFG (Data Flow Graph)
Summary
By using CxSAST with queries written in CxQuery, we created an abstraction layer to statically detect vulnerabilities that are exploitable. A single algorithm can detect Exploitable Path across multiple programming languages, and unlike other solutions on the market, CxSCA can easily extend support for more languages. Currently, Java and Python are already supported, with many more languages to follow. With CxSCA, Checkmarx enables your organizations to address open source vulnerabilities earlier in the SDLC and cut down on manual processes by reducing false positives and background noise, so you can deliver secure software faster and at scale. For a free demonstration of CxSCA, please contact us here. In the next post in this series, we'll look at some of the challenges we faced as we developed the Exploitable Path feature. 



